Como Integrar um LLM Offline ao Seu Computador: Quatro Abordagens
Outros posts sobre o tema em:
Como Criar um Pipeline em Python para Testar Modelos no Hugging Face
Parte 1 - Instalando o Ollama no Linux
Parte 2 - Instalando o Ollama no Windows
Parte 3 - Instalando o Ollama no Android pt.1
Parte 4 - Instalando o Ollama no Android pt.2
Neste vídeo, apresento quatro formas de integrar uma LLM offline ao seu fluxo de trabalho:
Lembre-se de que, por rodarem offline, essas aplicações dependem do poder computacional do seu computador, da quantidade de memória RAM e da capacidade de processamento da sua GPU.
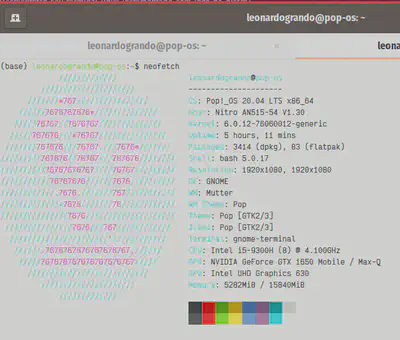
Lembrando que foi utilizado um notebook Acer Nitro com CPU Core i5 9300H, 16 GB de RAM e GPU Nvidia GeForce GTX 1650 para a realização destes testes.
Importante: Nunca use LLMs como oráculos ou fontes de informação definitiva; já encontrei vários erros em modelos, tanto online quanto offline. Utilize-os apenas como suporte para suas atividades.
1. No Terminal:
Acesse e utilize um LLM diretamente pelo terminal pelo Ollama, aproveitando sua flexibilidade e eficiência. Os links acima ensinam como instalá-lo. Windows, Linux, Android via aplicativo e via Termux.
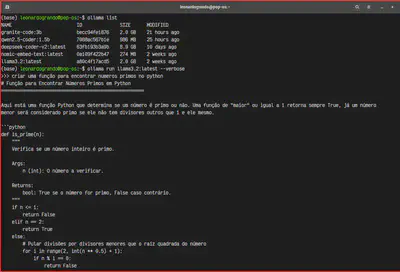
Alguns comandos interessantes:
- Para listar os modelos baixados na sua máquina
ollama list
- Para rodar o modelo, caso você não tenha este modelo ele vai efetuar o download e ativar o mesmo de forma local.
ollama run <modelo>
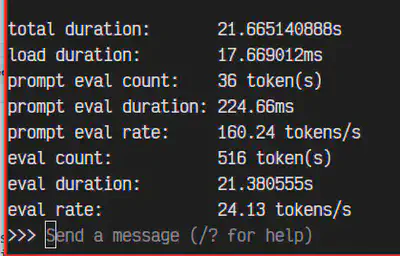
Para obter informações sobre a estatistica de performance do modelo em questão, incluir –verbose no final
ollama run <modelo> --verbose
Para sair do modelo é só digitar:
/bye
ou Control + D para sair.
2. Em uma Interface Gráfica (GUI):
Neste exemplo, utilizarei a interface disponível em OpenWebUI, que instalei via Docker para uma experiência mais intuitiva e que permite alterar/testar facilmente parâmetros do modelo utilizado.
Após a instalação do OpenWebUI, que no meu caso fiz via Docker
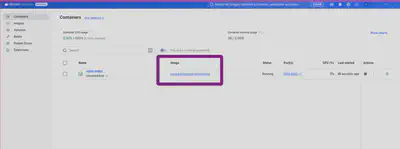
é só acessar o mesmo em seu navegador:
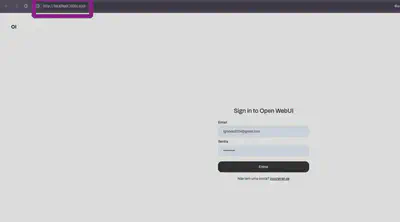
Ele vai pedir para criar uma conta para controle do acesso de usuários.
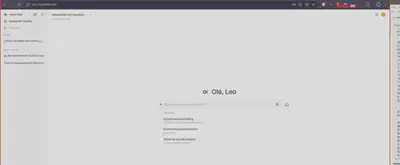
Observe que ele tem uma interface intuitiva, inclusive próxima a de outros LLMs online, é só escolher o modelo e comecar a utilizar
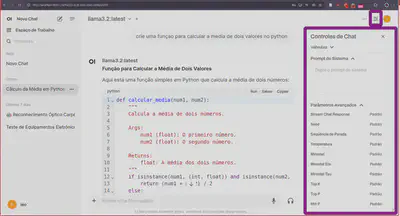
Observe que ele possui controles para você realizar alterações de parametros do modelo.
3. Como Extensão de Navegador:
Utilize o LLM através de uma extensão de navegador Chrome. Para isso, confira a Ollama UI, que oferece fácil integração. Ele permite escolher os vários modelos LLM que você tem em seu computador e permite salvar seus Chats. Para ativa-lo é só clicar no icone da extensão.
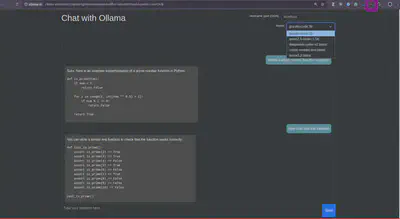
4. Em Aplicativos como o VSCode:
Existem várias extensões disponíveis para integrar LLMs a diversos aplicativos como o VS Code, o Obsidian, etc. Neste vídeo, utilizei o CodeGPT no VS Code, que proporciona funcionalidades adicionais diretamente no ambiente de desenvolvimento como auto-complete e um chat integrado com o seu código. Aqui encontrei um pouco de dificuldade em encontrar um modelo que rodasse neste computador. Para o recurso de auto complete o unico modelo que rodou em meus testes foi o Qwen2.5.
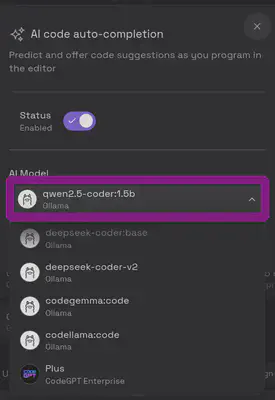
Conforme você for escrevendo o código ele ira sugerindo possíveis abordagens, aparece em cinza, só apertar TAB, como neste caso que escrevi uma função para encontrar numeros fibonacci, mas aqui na minha máquina é um processo lento:
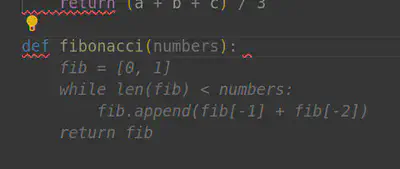
Você pode ver que elee está rodando com um comando:
ollama ps

Já para o Chat integrado para auxiliar no contexto do seu código, você pode escolher vários provedores, no meu caso o Ollama, e vários modelos, onde ele permite efetuar o download caso você não tenha no seu computador. No meu setup funcionou o Llama3.2:3B e o Granite-code:3b.
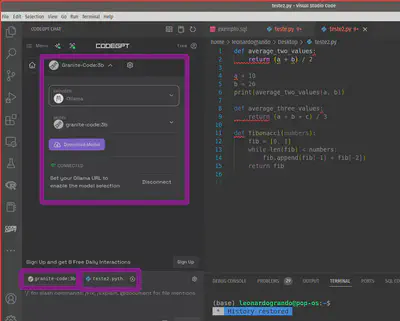
No meu caso o Granite foi melhor, permitindo o uso dos comandos /Fix (ele corrige seu código), /Explain (ele explica seu código), /Refactor (ele refatora seu código), /Document (Documenta seu código) e /Unit Test (ele cria unidades de testes para seu código).
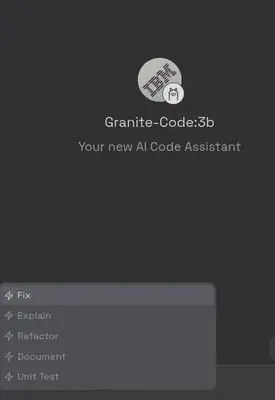
Criando uma unidade de teste para este código:
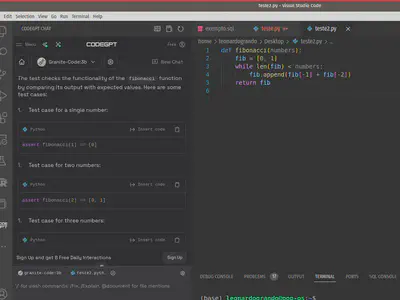
Observe que agora ele está usando o Modelo Granite

Lembrando que todas estas quatro aplicações ainda são experimentais e devem ser validadas antes de qualquer aplicação.
Sucesso a todos!
Leonardo Grando
Technology Ph.D. Candidate
My research interests include Agent-Based Simulation, Artificial Intelligence, Machine Learning.